Linked Data Fragments: cosa sono e come si usano
Maximilian Ventura – 8 Dicembre 2018 – Web semantico

La quantità di Linked Data presenti nel web sta aumentando negli ultimi anni. Lo dimostrano i dati forniti da DBpedia il punto di riferimento per la creazione e la sperimentazione di Linked Data. Come già abbiamo visto in articoli precedenti uno dei problemi più grandi per l’utilizzo live di questi dati è la necessità di avere uno SPARQL endpoint, cioè un POP (Point of Presence), un punto di accesso alla rete in grado di ricevere e processare richieste utilizzando il protocollo SPARQL.
Gli SPARQL endpoint richiedono molte risorse ai server e questo, obiettivamente, ne impedisce l’utilizzo su larga scala.
Una soluzione potrebbe essere quella di far ricadere il “peso” delle interrogazioni sul lato client, chiedendo agli utenti di scaricare tutto il database. Ma anche questa non è una soluzione perché semplicemente sposterebbe il problema senza risolverlo.
Linked Data Fragments
Cercare una via di mezzo tra questi due estremi ha portato, Ruben Verborgh ed i suoi collaboratori dell’Università di Ghent, alla teorizzazione e allo sviluppo dei Linked Data Fragments (LDF), dove il carico delle interrogazioni è suddiviso più equamente tra server e client. L’obiettivo dei Linked Data Fragments infatti è quello di rendere i client in grado di effettuare interrogazioni semantiche utilizzando il protocollo http.
I Linked Data sono formati da triple, questo concetto lo ritroviamo nei LDF sotto forma di Triple Pattern Fragment. Ogni Linked Data Fragment è costituito da:
- un pattern triplo come selettore
- un oggetto che effettua il conteggio dei metadati
- i controlli per recuperare qualsiasi altro frammento di pattern triplo dello stesso set di dati, in particolare altri frammenti a cui appartengono gli elementi corrispondenti
Per far funzionare tutto questo ovviamente occorrono i server ed i client (in grado di risolvere query SPARQL). Nella documentazione ufficiale, che trovate [qui], è possibile scegliere tra sette diversi tipi di server: JavaScript, Python, Perl,Ruby, PHP, Java e NetKernel. Noi useremo la versione JavaScript che richiede Node.js
In questo articolo vedremo:
- come si installa un server LDF
- come si inseriscono i dati
- come si effettuano le interrogazioni
Linked Data Fragments Tutorial
1. Linked Data Fragments Server
Avviamo la nostra macchina virtuale (Ubuntu Server 18.04.1 LTS) e installiamo Node.js, è richiesta la versione 4.0 (o superiore).
$ sudo apt install nodejse il server
$ [sudo] npm install -g ldf-serverA questo punto creiamo un file di configurazione in cui andremo a specificare quali sono le sorgenti dei nostri dati. Il server è molto flessibile e supporta vari formati:
- HDT files
- N-Triples documents
- Turtle documents
- JSON-LD documents
- SPARQL endpoints
Noi useremo solo dati in formato JSON-LD. Osservando il file di configurazione si possono notare le impostazioni per settare la porta del server, il numero di workers e l’origine dei dati. Nello stesso file è possibile richiamare diversi dataset, in questo esempio sono tre: Places, People, e Events.
{
"title": "Fontistoriche Linked Data Fragments Server",
"baseURL": "/",
"port": 5000,
"workers": 1,
"datasources": {
"composite": {
"title": "LDF - Fontistoriche",
"type": "CompositeDatasource",
"description": "Fontistoriche Linked Data Fragments",
"settings": {
"references": [
"Places",
"People",
"Events"
]
}
},
"Places": {
"hide": true,
"title": "Places",
"type": "JsonLdDatasource",
"description": "Luoghi",
"settings": {
"file": "/places.jsonld"
}
},
"People": {
"hide": true,
"title": "People",
"type": "JsonLdDatasource",
"description": "Personaggi storici",
"settings": {
"file": "/people.jsonld"
}
},
"Events": {
"hide": true,
"title": "Events",
"type": "JsonLdDatasource",
"description": "Eventi connessi ai personaggi storici",
"settings": {
"file": "/events.jsonld"
}
}
},
"logging": {
"enabled": true,
"file": "access.log",
"format": null
}
}Adesso andiamo a vedere nello specifico come deve essere strutturato un file jsonld per renderlo intellegibile dal nostro server.
2. Inserimento dati, le specifiche dei file jsonld
{
"@context": "http://schema.org/",
"@id": "https://fontistoriche.org/person",
"@type": "Person",
"name": "People",
"description": "Personaggi storici",
"People": [
{
"@id": "https://fontistoriche.org/papa-paolo-i/",
"@type": "Person",
"name": "Papa Paolo I",
"description": "Papa Paolo I è stato il 93º Papa della Chiesa cattolica, dal 29 maggio 757 alla sua morte.",
"gender": "Male",
"image": "https://fontistoriche.org/wp-content/uploads/papa-paolo-i.jpg",
"sameAs": "https://it.wikipedia.org/wiki/Papa_Paolo_I",
"birthDate": "0700",
"birthPlace": "Roma",
"deathDate": "0767-06-28",
"deathPlace": "Roma"
},
{
"@id": "https://fontistoriche.org/papa-stefano-iii/",
"@type": "Person",
"name": "Papa Stefano III",
"description": "Papa Stefano III, o IV secondo una diversa numerazione, viene considerato il 94º papa della chiesa cattolica, dal 1º agosto 768 alla sua morte. ",
"gender": "Male",
"image": "https://fontistoriche.org/wp-content/uploads/papa-stefano-iii.jpg",
"sameAs": "https://it.wikipedia.org/wiki/Papa_Stefano_III",
"birthDate": "0720",
"birthPlace": "Siracusa",
"deathDate": "0772-01-24",
"deathPlace": "Roma",
"performerIn": "Concilio Lateranense (769)",
"knows": "Pipino III (Pipino il Breve)"
},
{
"@id": "https://fontistoriche.org/papa-adriano-i/",
"@type": "Person",
"name": "Papa Adriano I",
"description": "Papa Adriano I è stato il 95º papa della Chiesa cattolica, dal 1º febbraio 772 al 795.",
"gender": "Male",
"image": "https://fontistoriche.org/wp-content/uploads/papa-adriano-i.jpg",
"sameAs": "https://it.wikipedia.org/wiki/Papa_Adriano_I",
"birthDate": "0700",
"birthPlace": "Roma",
"deathDate": "0795-12-25",
"deathPlace": "Roma"
}
]
}Nell’esempio ho riportato un pezzo del dataset “People”. Come vocabolario ho preferito utilizzare schema ma volendo si possono usare anche gli altri.
Adesso possiamo far partire il nostro server specificando qual è il file di configurazione.
$ ldf-server config.jsonDal browser visitiamo il seguente link:
http://localhost:5000/NOTA BENE: se si utilizza una macchina virtuale (come stiamo facendo noi), al posto di localhost occorre inserire l’indirizzo della macchina virtuale.
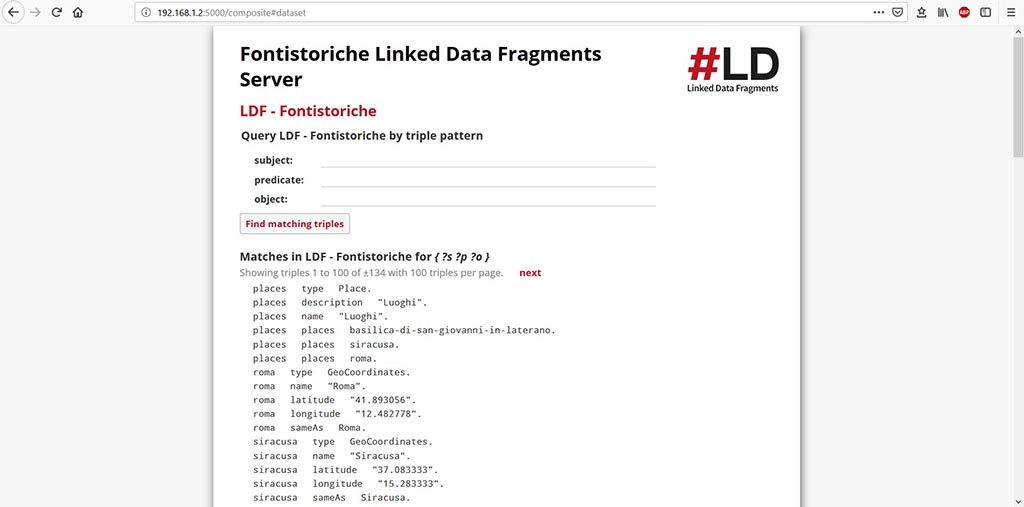
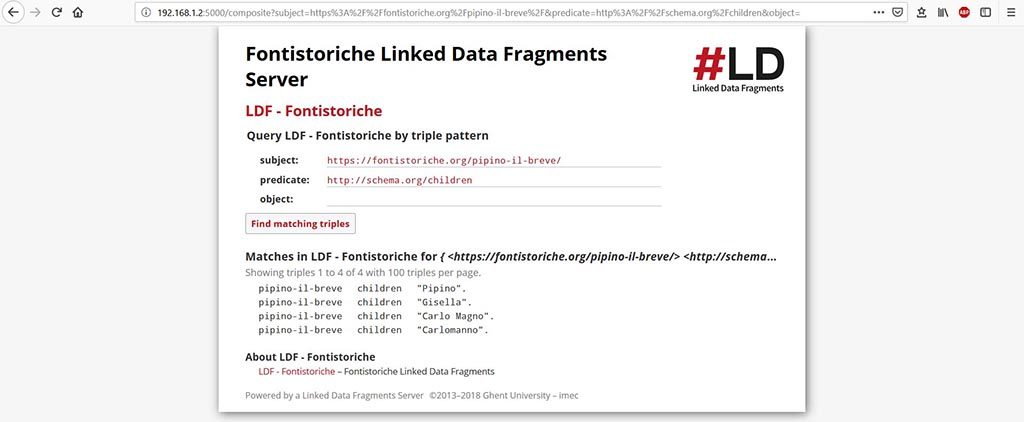
Il server risolve tutte le triple e ci indica anche il numero totale: 134. Ogni tripla è formata da un Soggetto, un Predicato ed un Oggetto.
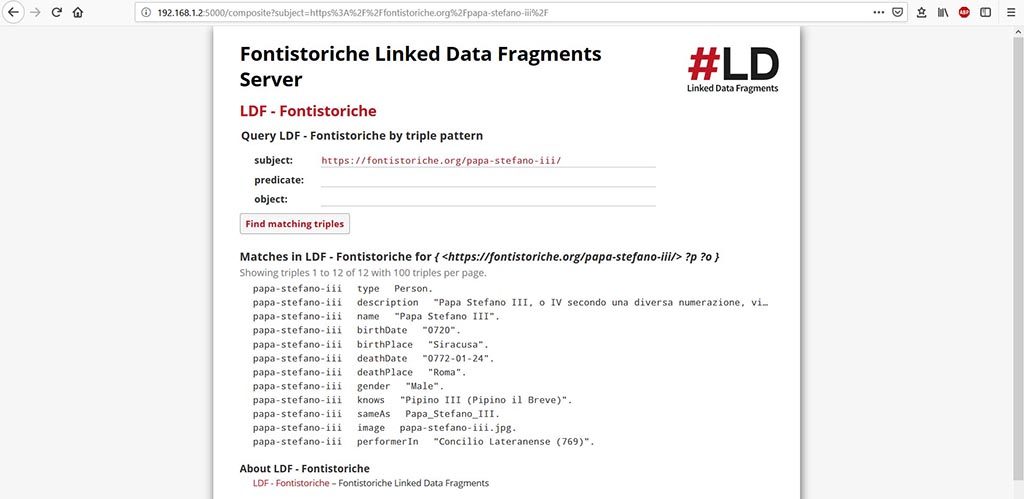
Cliccando sul Soggetto Stefano III avremo infatti l’elenco di tutte le triple (12) in cui compare. Proseguiamo nell’esplorazione e clicchiamo su “Roma”.

“Roma” con il valore di Oggetto è presente in 6 triple. Adesso clicchiamo su “roma” come Soggetto e vedremo i dati geografici che sono presenti nel dataset Places.

Possiamo anche eseguire query specificando il Soggetto ed il Predicato