
I linked data sono un set di buone pratiche e raccomandazioni per pubblicare e collegare dati strutturati sul web. I dati devono poter essere letti, interpretati e utilizzati da una macchina, ed il significato deve essere definito da una stringa di parole e marcatori (triple) per costituire un reticolo di dati connessi e collegabili ad altri set di dati, dando origine al Web Semantico.
Il web attuale è costituito da documenti html creati per poter essere letti e interpretati da umani. I link che tutti conosciamo collegano questa tipologia di documenti. Guardando l’immagine vediamo che il sito A è collegato al sito B e C utilizzando un link diretto. Ma senza questo collegamento non c’è modo di arrivare dal sito B al sito C, né tantomeno dal sito B al sito A, perché un link è unidirezionale.
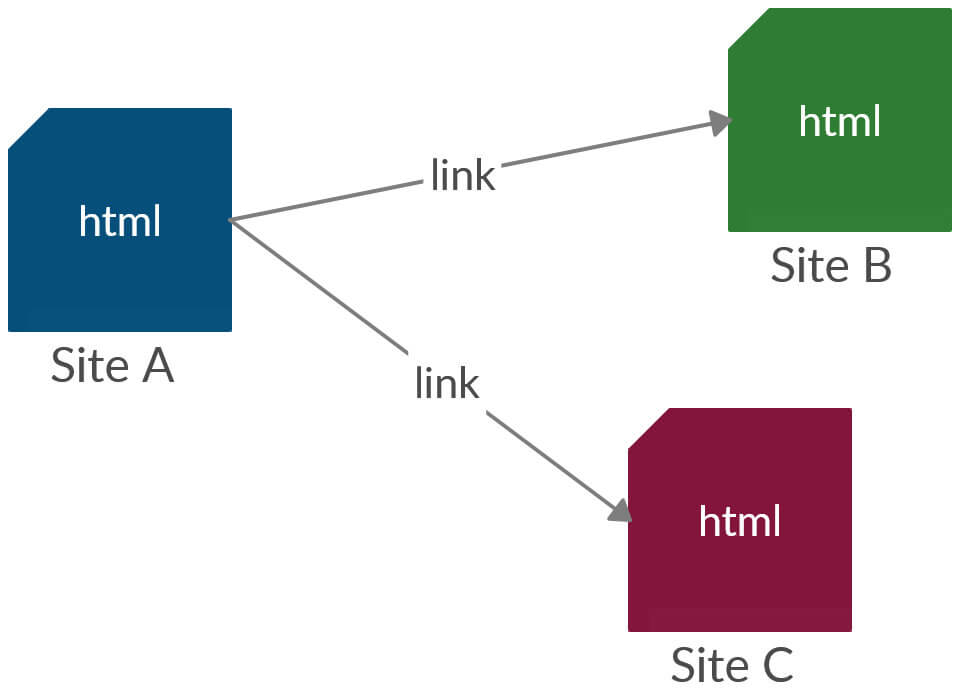
Fig. 1. Web di documenti.
Web semantico
Nel Web Semantico invece i linked data sono il mezzo attraverso il quale è possibile costruire una rete di connessioni; utilizzando dati strutturati ed un insieme di regole di inferenza, si rende possibile ad una macchina la possibilità di compiere “ragionamenti automatici”.
Il Web Semantico secondo Tim Berners-Lee è un’estensione del web attuale, nella quale all’informazione viene dato un significato ben definito, permettendo alle macchine e alle persone di cooperare.
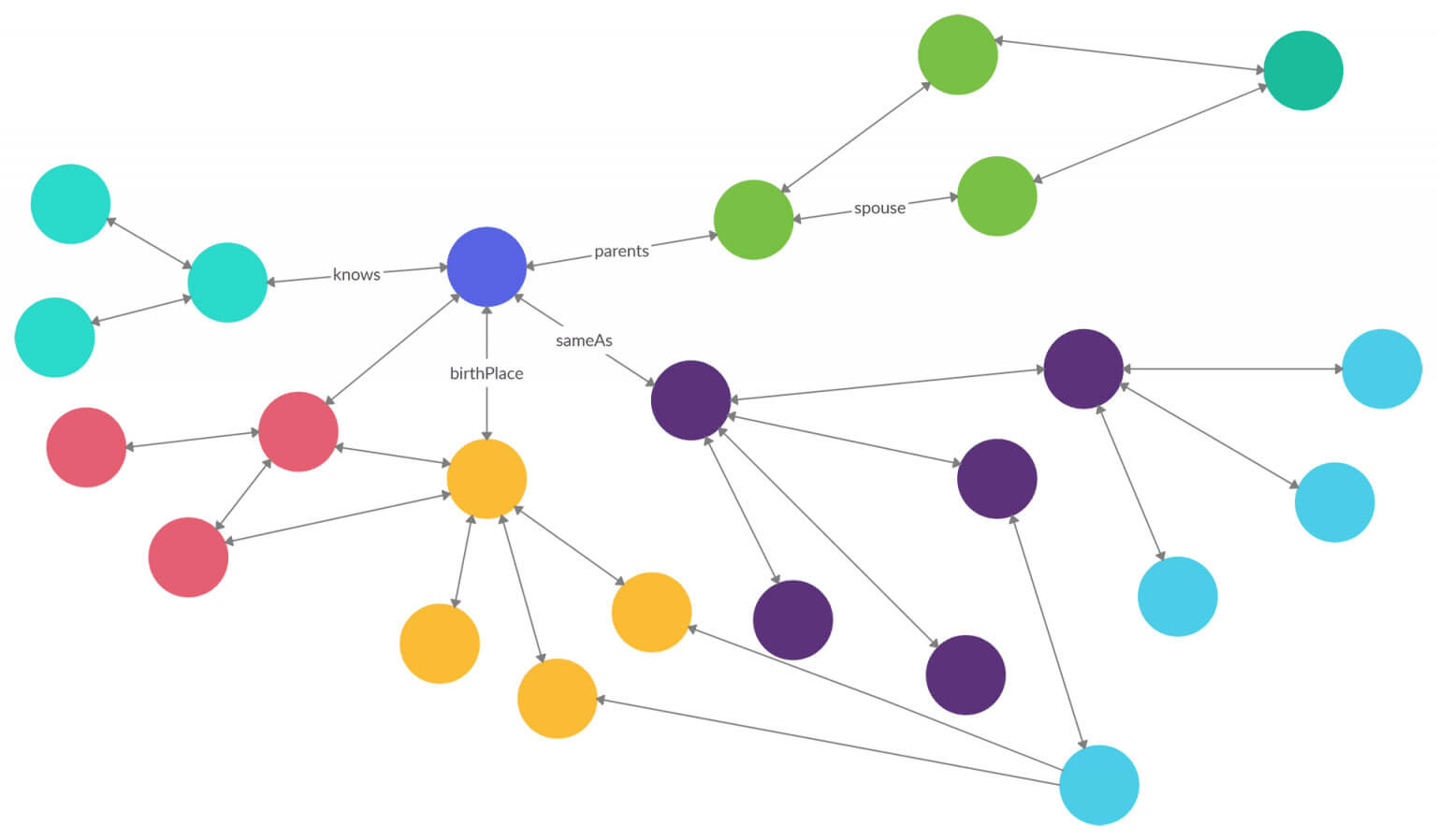
Fig. 2. Web Semantico.
L’inferenza nei linked data
Il concetto di inferenza è importante per capire cosa si intende quando si fa riferimento alla capacità di una macchina di compiere ragionamenti automatici. Con inferenza si intende il processo con il quale si passa da una proposizione accettata come vera ad una seconda la cui verità è dedotta grazie al contenuto della prima.
Facciamo un esempio, date queste 3 asserzioni:
Marco è figlio di Luigi
Bruna è figlia di Luigi
Luigi è figlio di Francesca
Possiamo dedurre che:
Marco e Bruna sono nipoti di Francesca
Marco è fratello di Bruna
Bruna è sorella di Marco
In pratica avendo i dati e delle regole ben definite è possibile, per una macchina, dedurre nuova conoscenza, cioè è possibile ricavare informazioni che non sono state direttamente inserite nel sistema.
L’invenzione dei linked data
L’idea dei linked data e del Web Semantico si deve a Tim Berners-Lee, colui che ha inventato il World Wide Web il 6 agosto 1991, pubblicando il primo sito web della storia. Il progetto in realtà risale al 1989 quando Berners-Lee lavorava con il collega belga Robert Cailliau ad un software per la condivisione dei documenti scientifici in formato digitale.
Circa 15 anni dopo, il 27 luglio 2006 Berners-Lee pubblica un documento ancora consultabile sul web, dove descrive i criteri per realizzare il Web Semantico:
- Utilizzare URI per identificare e dare un nome alle cose
- Utilizzare URI seguendo il protocollo HTTP affinché possano essere consultati
- Fornire informazioni utili quando qualcuno cerca le URI utilizzando standard come RDF e SPARQL
- Includere collegamenti ad altre URI per permettere di trovare più risorse.
Questi 4 criteri rappresentano il “come” ma ci sono ancora alcuni aspetti teorici e di forma che dobbiamo affrontare. Per esempio, come facciamo ad associare ai dati, gli attributi e le relazioni logiche?
Lo facciamo usando le ontologie.
Cosa sono le ontologie
Nell’ambito dei linked data, la parola ontologia indica una concettualizzazione di un dominio di conoscenza, in un linguaggio che può essere compreso dalle macchine.
Attraverso l’ontologia si specificano le classi, le relazioni semantiche tra classi, le proprietà associate ad un concetto e quindi si stabiliscono le regole di base che permettono i processi di inferenza alle macchine.
Se volessimo creare l’ontologia della pizza dovremmo creare una classe per ogni pizza che vogliamo descrivere. Ogni pizza potrà avere delle sottoclassi e delle relazioni con gli ingredienti.
Concettualizzare il sapere non è un’operazione semplice e neanche oggettiva, ma la grammatica che si utilizza per eseguire questo compito deve essere necessariamente condivisa, la grammatica dei linked data si chiama: RDF.
RDF
RDF è l’acronimo di Resource Description Framework ed è lo standard proposto dal consorzio W3C per la realizzazione del Web Semantico.
RDF quindi fornisce le regole per gestire la struttura logica ed esprimere le relazioni tra le informazioni, e lo fa utilizzando la logica dei predicati. Si tratta di un modello sintagmatico composto da tre elementi che danno forma ad una asserzione, tripla ostatement, composta da: soggetto, predicato e oggetto.
- Il soggetto è una qualunque risorsa definita da un URI, sarebbe meglio dire da un URL (poi vedremo perché)
- Il predicato è una proprietà specifica del soggetto o indica una relazione con l’oggetto e si identifica tramite URL
- L’oggetto può essere un valore: alfanumerico o un URL
Entriamo un po’ nei dettagli per dire che RDF è composto da 2 parti:
- RDF Model and Syntax che definisce il data model RDF e la sua codifica XML
- RDF Schema che permette di definire specifici vocabolari per i metadati
Ricapitolando: con RDF abbiamo le regole grammaticali necessarie per strutturare le asserzioni, RDFS ci serve per utilizzare quelle regole e costruire vocabolari per i metadati.
Graficamente, le relazioni tra soggetto, predicato e oggetto vengono rappresentate mediante grafi etichettati orientati, in cui le risorse vengono identificate come nodi (ellissi), le proprietà come archi orientati etichettati, e i valori corrispondenti a sequenze di caratteri come rettangoli.
Facciamo qualche esempio: nella prima asserzione diciamo che Frank conosce Victoria e nella seconda che Victoria è nata a Londra.
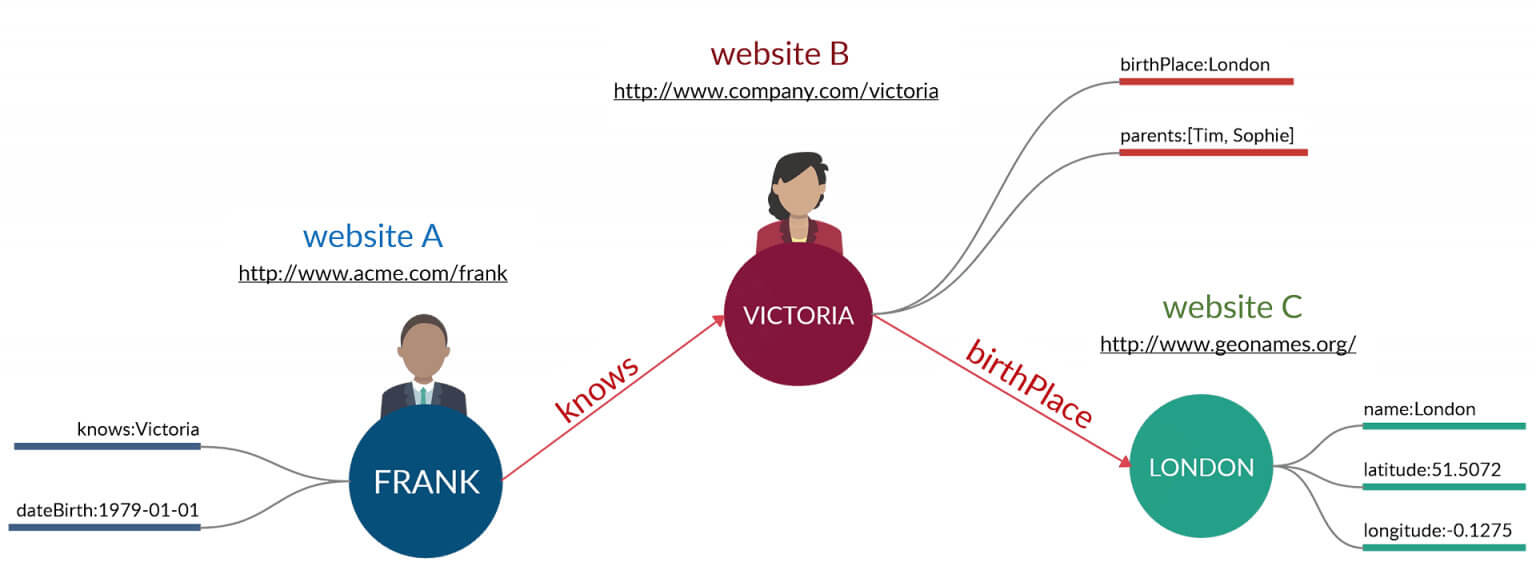
Fig. 3. Linked data, stuttura di una tripla.
Per un essere umano dire “Frank conosce Victoria” o “Victoria conosce Frank” è la stessa cosa. Per una macchina no e devono essere considerate come due triple diverse anche se equivalenti.
Nella prima tripla il soggetto è correttamente espresso con una URL, l’oggetto è un valore letterale e la proprietà ha nome particolare: knows che dà senso a tutta l’asserzione.
Nella seconda tripla è Victoria il soggetto quindi non può essere espresso come valore letterale.
Sia knows che birthPlace sono due proprietà che appartengono ad un vocabolario che si chiama: schema.
Vocabolari e metadati
L’obiettivo dei vocabolari è fornire una raccolta di termini condivisi e validati che permettono di esprimere le diverse relazioni tra le entità. Se vogliamo usare il vocabolario schema e vogliamo indicare il luogo di nascita di una persona dovremo necessariamente utilizzare il termine: birthPlace.
In questo caso l’URL della proprietà è:
E tutta la tripla:
http://www.company.com/victoria > http://schema.org/birthPlace > Londra
Possiamo indicare genericamente tutti questi dati come metadati, cioè come dati che descrivono altri dati; birthPlace non è un dato in sé ma è fondamentale perché descrive una proprietà e permette ad una macchina di capire il significato della parola Londra.
Sul sito Linked Open Vocabularies sono presenti 697 vocabolari, ci sono quelli per descrivere ambiti specifici ed altri generalisti come: Dublin Core e schema.
Cosa rende i linked data così speciali?
Per capirlo è sufficiente dare un’occhiata all’immagine sotto.
Con i linked data stiamo collegando i dati provenienti da 3 siti diversi.
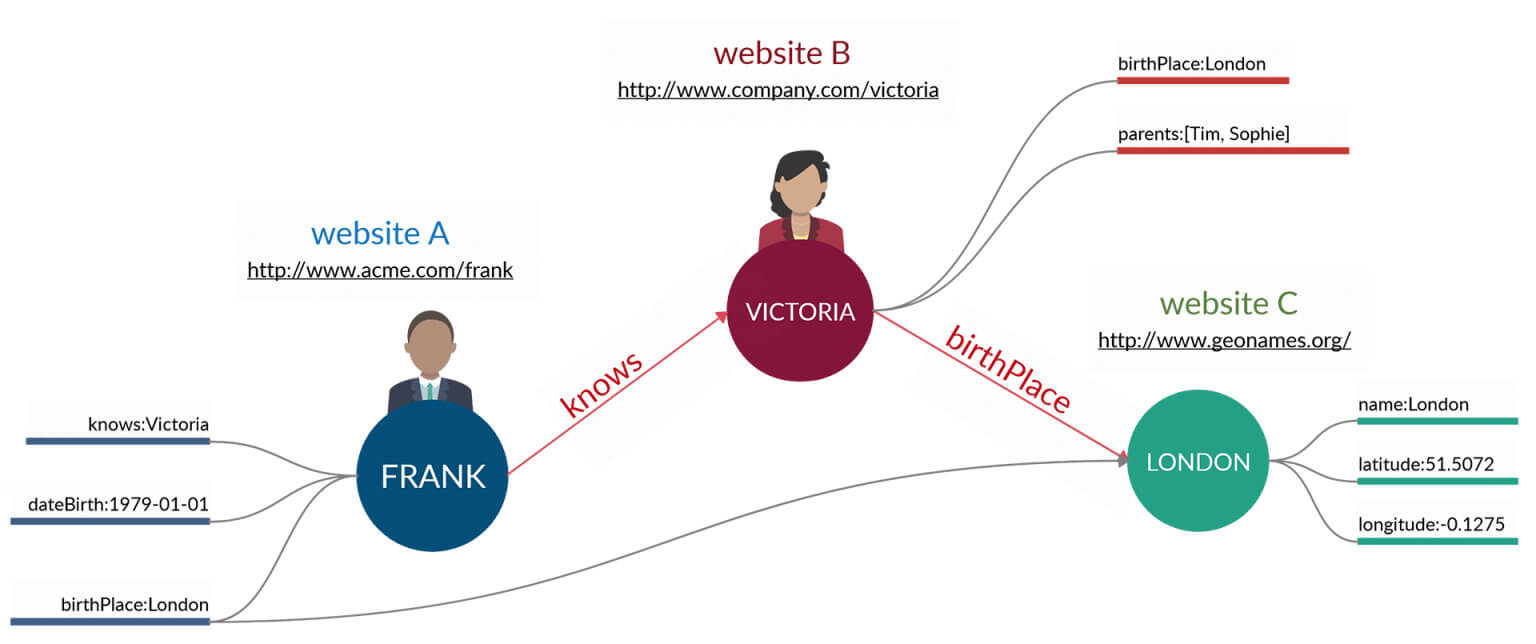
Fig. 4. Linked data, come si collegano i dati ad altri dataset.
E questa serie di connessioni con database già strutturati amplia i nostri stessi dati. Se anche Frank è nato a Londra, noi possiamo fare riferimento alle informazioni presenti su geonames.
Ma non solo, uno degli aspetti più interessanti è la possibilità di eseguire interrogazioni complesse, non basate esclusivamente sulle parole chiave.
Un esempio di quello che è possibile estrapolare da una montagna di linked data la troviamo nel video di una conferenza TED tenutasi nel 2009 da Tim Berners-Lee.
Ad un certo punto Berners-Lee cerca su Google: “What proteins are involved in signal transduction and are related to pyramidal neurons?”.
Il motore di ricerca restituisce 223.000 risultati ma nessunodi questi risponde alla domanda. Possiamo immaginare una quantità enorme di query che non sono e non possono essere ricorrenti.
Eppure la risposta c’è già, e si trova nei dati. Infatti poco dopo viene mostrato come grazie a database realizzati seguendo la logica dei linked data sia possibile trovare la soluzione, ci sono 32 proteine che hanno queste caratteristiche.
Quindi non solo colleghiamo dati ma poniamo le basi per trovare risposte a domande che ancora non abbiamo fatto.
Risorse e dataset in formato linked data
La quantità di dati e progetti che utilizzano i linked data sta crescendo da diversi anni. Sebbene le problematiche connesse non siano poche, i vantaggi sono enormi. La pandemia causata dal COVID-19 per esempio ha fatto nascere tutta una serie di progetti con dati aperti e accesibili.