
Il Machine Learning o apprendimento automatico rappresenta un insieme di metodi sviluppati negli ultimi decenni in varie comunità scientifiche che “fornisce ai computer l’abilità di apprendere senza essere stati esplicitamente programmati”.
Applicare questi metodi per la trascrizione automatica di manoscritti vuol dire avere un algoritmo in grado di riconescere i caratteri. Generalmente si parla di OCR (Optical Character Recognition) quando abbiamo bisogno di un programma in grado di estrarre i contenuti in formato testo da un’immagine. Nel caso specifico un OCR avanzato in grado di leggere i testi scritti a mano.
Cosa c’entra quindi il Machine Learning con l’OCR? C’entra molto perché più dati forniamo al nostro programma e maggiore sarà la quantità di lettere che potrà estrapolare dalle immagini.
In questo articolo vedremo come utilizzare alcuni strumenti open source per la trascrizione di manoscritti. Il tool che ho utilizzato si chiama Ocropy, su GitHub sono presenti le specifiche del progetto.
Tutorial per imparare ad usare Ocropy
1. Installazione
Incominciamo installando (su un pc con Ubuntu o su una macchina virtuale) le dipendenze necessarie:
$ mkdir workingcopy/
$ cd workingcopy/
$ sudo apt install git
$ git init .
$ git pull https://github.com/tmbdev/ocropy
$ sudo apt-get install $(cat PACKAGES)
$ wget -nd http://www.tmbdev.net/en-default.pyrnn.gz
$ mv en-default.pyrnn.gz models/
$ sudo python setup.py install2. Le immagini
Per avere dei buoni risultati sono necessarie immagini .tif con un’alta risoluzione: 300 DPI o più. Per eseguire questo training ho utilizzato le immagini del seguente manoscritto:
Engelberg, Stiftsbibliothek, Cod. 89, f. 1r
De gratia et libero arbitrio Aurelii Augustini et Bernardi Claraevallensis
http://www.e-codices.unifr.ch/it/bke/0089/1r/0/Sequence-172

Fig. 2. Trascrizione del manoscritto
4. Training
Estraiamo i dati da gt-new.html con la seguente riga
$ ocropus-gtedit extract gt-new.htmlil risultato sarà la creazione di una serie di file in formato testo inseriti in sottocartelle, una per ogni immagine, all’interno della cartella principale bke-0089.
Per cominciare la fase di training creiamo due cartelle: train e test. Nella prima mettiamo il 90% dei nostri file e il rimanente 10% nell’altra cartella, quali file scegliere per fare il test è a nostra discrezione. La cosa importante è avere le immagini ed i testi a cui fanno riferimento nella stessa cartella. Faccio un esempio: all’immagine 01000a.bin.png corrisponde il testo 01000a.gt.txt Entrambi i file devono essere presenti nella stessa sotto cartella.
Fig. 3. Training dei dati
5. Training - opzioni
Nella riga di comando prima di “myModel”, potete inserire una serie di opzioni che possono migliorare il riconoscimento dei caratteri. La cosa migliore è cercare un equilibrio tra il tempo che avete a disposizione e la quantità di calcoli che volete eseguire, tenendo presente che questo è solo il primo training, ammesso che ne vogliate fare altri, e quindi la quantità di errori per modello non potrà scendere oltre una certa soglia.
-F questo parametro permette di modificare il numero di iterazioni dopo il quale il modello viene salvato (parametro di default: 1000)
-d 1 permette di vedere una visualizzazione grafica del processo di training in corso (se avete una versione desktop di ubuntu)
-S specifica quanti hidden layer vogliamo, quindi quanto deve essere “profonda” la nostra rete neurale (parametro di default: 100)
-N quante righe di training deve calcolare prima di fermare il processo (parametro di default: 1.000.000, sì un milione!)
Ecco perché per eseguire il mio test ho aumentato la quantità di hidden layer ma ho diminuito il numero di righe.
6. Valutazione e scelta dei modelli
Ricordate la cartella test, con il 10% dei file conservati? È arrivato il momento di usarli per valutare i modelli che abbiamo creato. Sulla riga di comando facciamo eseguire questo codice:
for i in *.pyrnn.gz; do
echo "$i" >> modeltest
ocropus-rpred -m $i test/*/*.bin.png
ocropus-errs test/*/*.gt.txt 2>>modeltest
doneIn questo modo vengono utilizzati tutti i modelli che abbiamo salvato per riconoscere i caratteri presenti nelle immagini che abbiamo messo nella cartella test. A schermo vengono visualizzati gli errori, come numero totale e come percentuale, per ciascuno modello. Inserendo i dati in un foglio di calcolo otteniamo questo grafico. A partire dal modello 8 notiamo che i valori si stabilizzano su una percentuale di errore pari al 10%. Anche se facciamo calcolare più modelli la percentuale non si abbassa di molto.
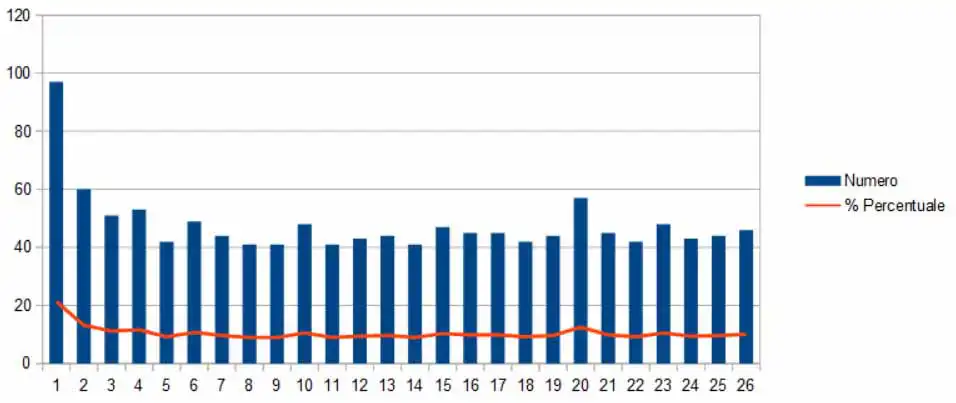
Fig. 4. Distribuzione degli errori sui vari modelli
7. Utilizzo dei modelli ed estrazione dei dati
Abbiamo creato 26 modelli, tra questi ne scegliamo uno che abbia una bassa percentuale di errore e lo usiamo come base per il riconoscimento. Nella cartella bke-0089 ho inserito le tre immagini ed ho eseguito nuovamente le istruzioni riportate nel paragrafo Preparazione dei dati. Facciamo partire il comando:
$ ocropus-rpred -n -m myModel-00009000.pyrnn.gz bke-0089/*/*.bin.pngper visualizzare il testo estratto possiamo usare:
$ ocropus-hocr bke-0089/*.bin.png -o bke-0089.htmlin questo modo creeremo il file bke-0089.html. Per essere precisi si tratta di un tipo particolare di formato chiamato hOCR. Possiamo aprirlo con un browser e vedremo tutte le righe che OCRopy è riuscito ad estrapolare, ma se analizziamo il codice sorgente sono riportate, per ogni linea, le righe di allineamento con il documento originale.
Machine learning e abbreviazioni. Considerazioni finali
I manoscritti presentano generalmente molte abbreviazioni, simboli convenzionali utilizzati al posto di uno o più caratteri, ciò rende la lettura un po’ faticosa per i non addetti ai lavori.
A tal proposito vorrei citare il volume di Adriano Cappelli Dizionario di abbreviature latine e italiane, uno dei testi più importanti per lo studio della paleografia.
Del machine learning mi ha positivamente sorpreso proprio questa capacità, riconoscere e sciogliere abbreviazioni che a volte differiscono per poco dalle lettere “normali”.
Nelle considerazioni finali non può mancarare la domanda “è possibile riutilizzare i modelli creati con altri manoscritti?” Sì ma il risultato dipende dal manoscritto utilizzato. Se i caratteri sono morfologicamente simili allora otterremo buoni risultati, altrimenti sarà molto più conveniente creare un altro training di dati.