Dal linguaggio naturale a SPARQL: un approccio controllato basato su LLM per generare query
Maximilian Ventura – 19 ottobre 2025 – Tutorial

Nel corso di questi anni abbiamo avuto modo di effettuare qualche sperimentazione con i Linked Data e SPARQL. Conosciamo tutti le potenzialità di questi strumenti ma sappiamo anche bene quanto sia difficile sfruttarli senza una buona conoscenza tecnica.
L’introduzione degli Large Language Models (LLM) ha aperto nuove strade. Quindi, perché non permettere ad un utente di interrogare l’immensa base di conoscenza di Wikidata scrivendo semplicemente una query in linguaggio naturale?
Questo lavoro nasce proprio dal tentativo di affrontare in modo sistematico il problema della traduzione da linguaggio naturale a query SPARQL eseguibili, utilizzando LLM ma inserendoli all’interno di una pipeline controllata, vincolata e verificabile.
1. Rigidità di SPARQL e ambiguità del linguaggio naturale
SPARQL è un linguaggio rigido, non ammette approssimazioni, placeholder, omissioni o interpretazioni. Una query è formalmente valida oppure non viene eseguita. Questo lo rende molto diverso dai contesti in cui gli LLM danno il meglio di sé, come il testo narrativo o argomentativo.
I primi tentativi di utilizzare direttamente un LLM per generare query SPARQL a partire da domande in linguaggio naturale mostrano risultati altalenanti, in alcuni casi la query è corretta, in altri presenta errori sintattici, proprietà inesistenti, variabili non legate o parti mancanti. In tutti questi casi l’endpoint SPARQL non restituisce nulla e il sistema fallisce.
Il problema non è soltanto sintattico. Anche quando la query è formalmente corretta, può essere semanticamente sbagliata, una proprietà non appropriata, un’entità ambigua, una relazione mal interpretata producono risultati errati o fuorvianti. Da qui nasce l’esigenza di ridurre lo spazio di libertà del modello e di affiancargli strumenti strutturali.
2. Guidare il modello LLM con il retrieval delle proprietà di Wikidata
Il passaggio successivo del progetto infatti è stato spostare il focus da “come scrivere un prompt migliore” a “come costruire una pipeline che renda difficile sbagliare”.
In Wikidata, le query SPARQL si basano essenzialmente su due tipi di identificatori:
- QID: che identificano le entità (persone, luoghi, concetti, opere, ecc.)
- PID: che identificano le proprietà, cioè le relazioni tra entità o tra entità e valori
Un LLM che lavora solo sul testo deve “indovinare” entrambi. Questo è esattamente il punto debole. Il progetto affronta il problema separando i compiti e introducendo una fase di retrieval strutturato prima della generazione della query.
3. Architettura generale della pipeline
Il sistema è organizzato come una pipeline a più stadi, in cui ogni passaggio produce un’informazione più strutturata della precedente:
- L’utente scrive una domanda in linguaggio naturale;
- La domanda viene inviata al backend dell’applicazione;
- Il backend tenta di individuare le entità menzionate (QID);
- La domanda viene trasformata in un embedding vettoriale;
- L’embedding viene usato per recuperare le proprietà (PID) più rilevanti;
- Il modello linguistico genera la query SPARQL usando QID e PID come vincoli;
- La query viene controllata e, se necessario, rigenerata;
- La SPARQL finale viene restituita al client, che può inviarla all’endpoint di Wikidata.
Questa separazione permette di affrontare problemi diversi con strumenti diversi, invece di delegare tutto a un singolo passaggio di generazione testuale.
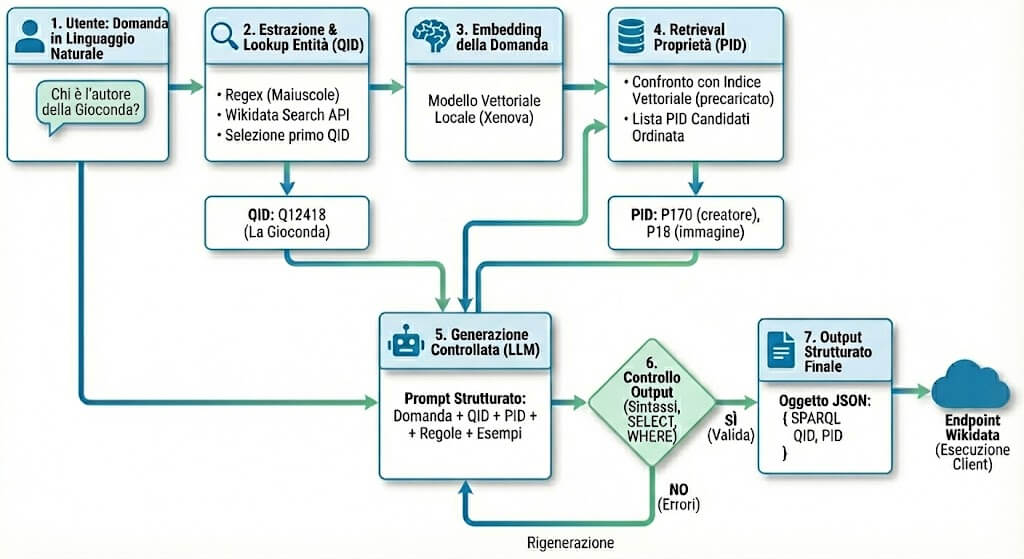
4. Estrazione e lookup delle entità (QID)
Il primo passaggio strutturato riguarda le entità. A partire dalla domanda dell’utente, il sistema estrae potenziali “soggetti” usando una strategia volutamente semplice: una regex che individua sequenze di parole con iniziale maiuscola.
Questi termini vengono poi inviati alla Wikidata Search API, che restituisce una lista di entità candidate. Il sistema seleziona il primo risultato per ranking e ne ricava il QID.
Questa fase non è una disambiguazione completa. È una scelta consapevole, lo scopo è fornire al modello un ancoraggio iniziale, non risolvere ogni ambiguità possibile. Il limite è noto, in presenza di termini ambigui, il QID scelto potrebbe non essere quello inteso dall’utente.
5. Embedding della domanda
Una volta ottenuti i QID candidati, il sistema calcola l’embedding vettoriale della domanda completa, non dei singoli termini. Questo embedding rappresenta il significato complessivo della richiesta.
Il calcolo avviene localmente, usando un modello di embedding multilingua (paraphrase-multilingual-MiniLM-L12-v2) caricato tramite Xenova Transformers in ambiente Node.js. Questa scelta consente di evitare chiamate esterne per l’embedding e di mantenere il controllo sull’intera pipeline.
6. Retrieval delle proprietà (PID)
Qui si trova uno degli elementi centrali del progetto.
In una fase offline è stato costruito un dizionario vettoriale delle proprietà di Wikidata. Ogni proprietà (PID) è stata rappresentata tramite il suo testo descrittivo (label, descrizione, e metadati rilevanti) e trasformata in un embedding. Questi vettori sono stati caricati in un database vettoriale.
Quando arriva una nuova domanda, l’embedding della query viene confrontato con questo indice. Il risultato è una lista ordinata di proprietà candidate, cioè le relazioni che semanticamente sembrano più pertinenti rispetto alla richiesta dell’utente. L’obiettivo è ridurre il rischio di proprietà inventate o inappropriate.
7. Generazione controllata della query SPARQL
Solo a questo punto entra in gioco l’LLM. Al modello viene fornito un contesto strutturato composto da:
- la domanda originale in linguaggio naturale;
- le entità individuate (QID);
- l’elenco delle proprietà candidate (PID);
- un insieme di regole formali molto rigide;
- esempi di query SPARQL complete e corrette (few-shot).
Al modello non viene chiesto di “inventare” una query, ma di combinare elementi già selezionati rispettando una forma obbligata. Questo riduce sensibilmente sia gli errori sintattici sia quelli semantici.
8. Controllo dell’output e rigenerazione
La query generata non viene accettata automaticamente. Viene prima sottoposta a controlli automatici: presenza di SELECT, blocco WHERE completo, assenza di placeholder o parti omesse.
Se la query non supera questi controlli, il sistema avvia una rigenerazione con istruzioni più stringenti. Questo meccanismo non garantisce la perfezione, ma riduce in modo significativo la probabilità di restituire una query inutilizzabile.
9. Cosa restituisce il sistema
Il backend non esegue direttamente la query su Wikidata. Restituisce invece un oggetto strutturato che contiene:
- la query SPARQL finale;
- le proprietà utilizzate;
- le entità individuate.
Questo consente trasparenza, verificabilità e la possibilità di riutilizzare la query in altri contesti.
10. Limiti emersi
Nonostante l’approccio controllato, restano limiti strutturali.
Il primo è l’ambiguità delle entità: il sistema può scegliere un QID errato senza rendersene conto. Il secondo riguarda la complessità delle domande, interrogazioni semplici funzionano bene, mentre richieste complesse o multi-vincolo richiederebbero ulteriori livelli di controllo e validazione.
Questi limiti non derivano da un’implementazione carente, ma dalla natura stessa del problema: tradurre linguaggio naturale in un linguaggio formale richiede sempre una riduzione dell’ambiguità che non può essere completamente automatica.
11. Conclusioni
Il progetto ha dimostrato che la trasformazione automatica di domande in linguaggio naturale in query SPARQL richiede vincoli e controllo, ma che anche un approccio guidato (retrieval delle proprietà e regole nel prompt) non garantisce, da solo, la generazione sistematica di query sempre corrette ed eseguibili.
Il principale limite emerso è la fragilità della generazione, bastano piccoli errori sintattici o strutturali per rendere la query inutilizzabile. Questo risultato è coerente con quanto riportato in letteratura, dove la generazione di SPARQL con LLM viene spesso descritta come un problema ancora aperto sul piano dell’affidabilità.