Transkribus: il tutorial per la trascrizione di manoscritti con l’Intelligenza Artificiale
Maximilian Ventura – Ultimo aggiornamento: 11 Gennaio 2025 – Tutorial

Abbiamo recentemente aggiornato il tutorial di Transkribus.
Transkribus è una piattaforma basata sull’intelligenza artificiale per la digitalizzazione, il riconoscimento automatico e la trascrizione di documenti storici, sia a stampa che manoscritti. Il progetto ha origine nell’ambito del programma europeo READ (Recognition and Enrichment of Archival Documents), finanziato con fondi Horizon 2020, ed è dal 2019 sviluppato e mantenuto da READ-COOP SCE.
La piattaforma mette a disposizione strumenti integrati per:
- la trascrizione manuale e automatica dei testi;
- l’addestramento di modelli personalizzati di riconoscimento;
- la ricerca avanzata nelle trascrizioni;
- l’annotazione e la marcatura dei documenti;
- la collaborazione tra utenti;
- l’esportazione in diversi formati standard.
Grazie a queste funzionalità, Transkribus si configura come una soluzione completa per la gestione, lo studio e la valorizzazione del patrimonio documentario.
Come usare Transkribus
Vai sul sito: https://www.transkribus.org/it registrati e accedi alla piattaforma.
Hai a disposizione tre modalità principali per elaborare i tuoi documenti storici:
- Riconoscimento rapido del testo
- Utilizzo di modelli pubblici pre-addestrati
- Addestramento di modelli personalizzati
Nei paragrafi seguenti vedremo tutte le modalità.
1. Riconoscimento rapido del testo
Quando non è necessario ricorrere a un modello specifico, oppure si opera con lingue e scritture di uso comune, la funzione di riconoscimento rapido rappresenta la soluzione più immediata: basta selezionare la lingua, caricare il documento e il testo viene generato in pochi istanti. Le pagine che sono state caricate vengono salvate e possono essere trovate nella raccolta denominata “Riconoscimento testo rapido”.
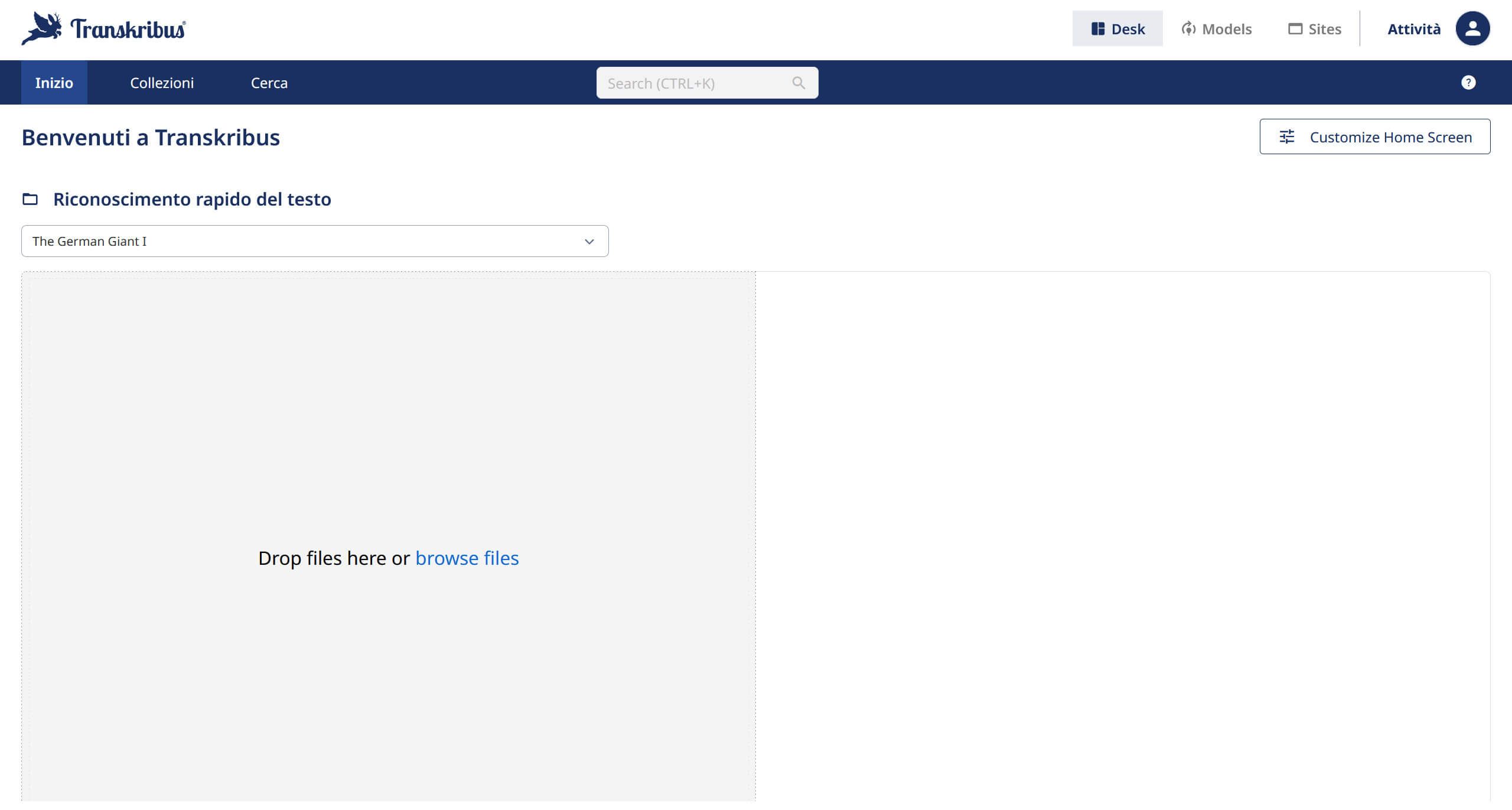
Puoi caricare i tuoi documenti (JPEG/JPG, TIFF e PNG fino a 20MB) e scegliere uno dei modelli per il riconoscimento rapido del testo. La scelta del modello è semplice grazie alle note descrittive disponibili per ciascuno di essi. Una volta caricata l’immagine e scelto il modello l’elaborazione si avvia in automatico e a questo punto sarà possibile editare il testo cliccando sul pulsante: Open in Editor.
2. Utilizzo di modelli pubblici pre-addestrati
Clicca la voce Collezioni del menu, crea una collezione, aggiungi i tuoi documenti e clicca su Create document.
La piattaforma non è sempre velocissima e quindi potresti dover aspettare un po’ prima di vedere i documenti nella tua collezione.
Seleziona i documenti che vuoi trascrivere e clicca sul pulsante “Processo con IA“. Puoi scegliere uno tra i tanti modelli presenti già nell’applicativo. I cosiddetti Super Model, come The Text Titan I sono disponibili facendo un upgrade dell’abbonamento. (per conoscere i costi clicca qui) Ogni modello ha una propria pagina con i dettagli e le metriche.
2.1. I modelli
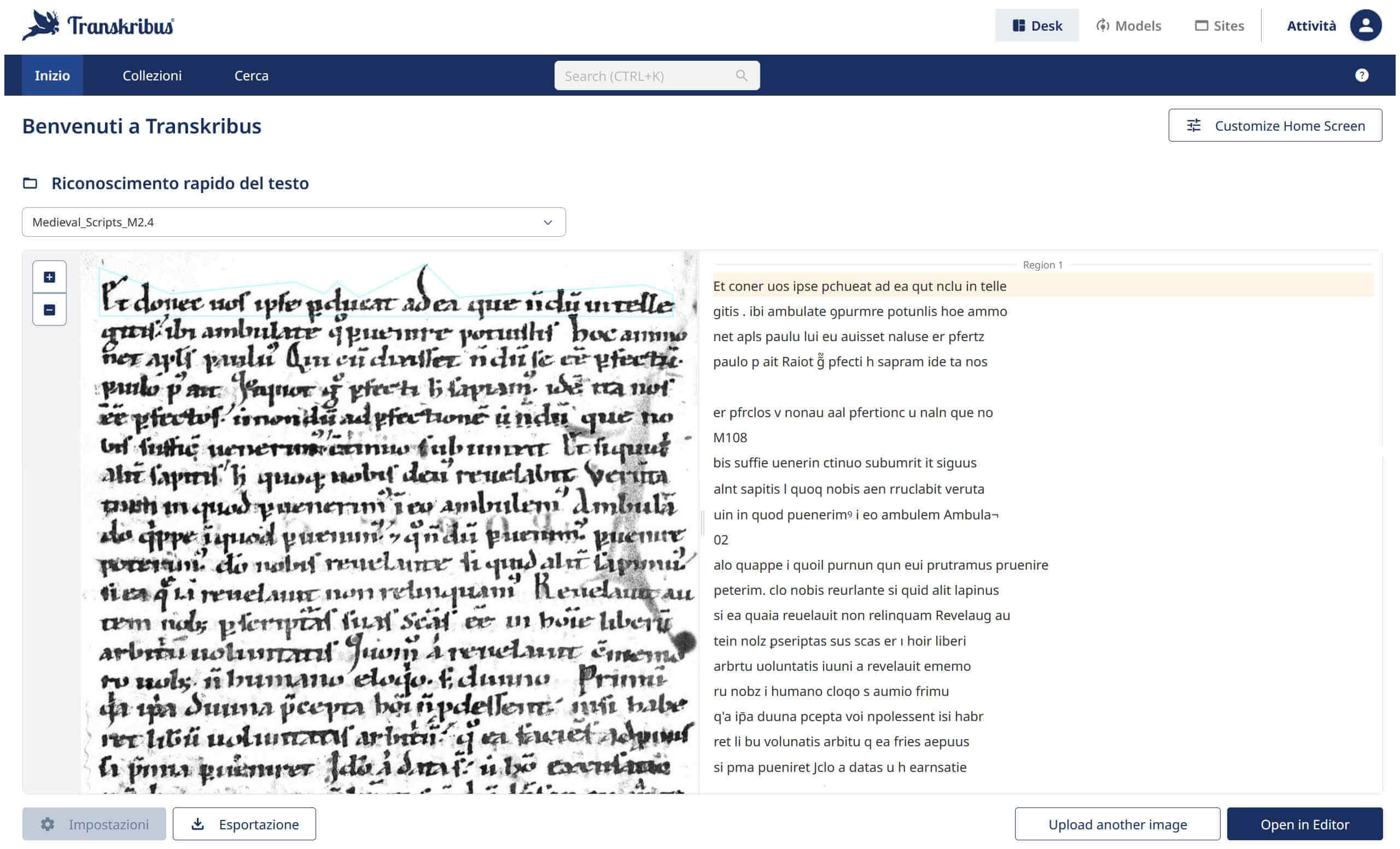
Cliccando su questo indirizzo: https://app.transkribus.org/models è possibile visionare tutti i modelli presenti nella piattaforma. Nella pagina sono presenti filtri per lingua e anche per tipologia (scritto a mano / stampato). Nell’esempio riportato di seguito possiamo vedere che il modello Medieval_Scripts_M2.4 è stato addestrato su oltre 7 milioni di parole: corrispondenti a 24.764 pagine di training e 179 di validazione. Il risultato raggiunto è un CER pari al 7.1%
2.2. Cos’è il CER e come si calcola
CER è l’acronimo di Character Error Rate ed è la metrica standard per misurare l’accuratezza.

Facciamo un esempio:
- Testo corretto:
dominus(7 caratteri) - OCR:
doninus→ 1 errore (scambio di lettere) - CER = 1/7 ≈ 14%
Un solo errore in una parola di 7 caratteri ha un peso rilevante. Per questo motivo un modello con un CER al di sotto del 10% è discreto ma è necessario fare delle correzioni.
2.3. Correzione manuale
Nella versione gratuita può capitare di dover aspettare la coda di elaborazione di altri utenti. Una volta completato il riconoscimento, cliccando su ogni singolo documento caricato, sarà possibile correggere gli errori. Transkribus permette di esportare sia le immagini che il testo in formato txt e xml. Si possono inoltre inserire dei tag come: abbreviazione, paragrafo, heading ecc.
3. Addestramento di modelli personalizzati
Prima di addestrare un modello di riconoscimento del testo è indispensabile predisporre il Ground Truth, cioè le immagini affiancate dalle loro trascrizioni corrette, che fungeranno da base di apprendimento per l’IA.
Il Ground Truth è il set di dati corretti (immagini + trascrizioni esatte) usato come riferimento per addestrare un modello. In Transkribus indica il materiale costituito dalle pagine digitalizzate e dalle relative trascrizioni verificate. È fondamentale che queste ultime siano prive di errori, poiché ogni errore nel Ground Truth verrà appreso dal modello e riprodotto nelle trascrizioni.
La quantità di dati necessari dipende dal tipo di fonte e dal numero di mani scrittorie coinvolte. In genere servono tra le 5.000 e le 15.000 parole (pari a circa 25–75 pagine) per avviare un addestramento efficace. Le reti neurali imparano rapidamente, ma la qualità cresce con l’aumentare dei dati forniti.
Per testi a stampa, circa 5.000 parole possono essere sufficienti per raggiungere un buon livello di accuratezza. Per i manoscritti, invece, è consigliabile almeno 10.000 parole per ogni mano. I modelli basati su dataset molto ampi (oltre 100.000 parole) e su più mani della stessa epoca o area geografica riescono spesso a trascrivere anche scritture non incluse nel training, sebbene con prestazioni leggermente inferiori rispetto al dato di validazione.
PRIMA HTR Model — Italian Early Modern Manuscripts (late 16th–18th c.)
È disponibile anche un modello HTR specifico per l’italiano moderno antico, pubblicato dal progetto europeo PRIMA – Manuscripts in the Age of Print. Si tratta di un modello addestrato su manoscritti tra la fine del XVI e il XVIII secolo, pensato per riconoscere grafie corsive e cancelleresche tipiche dell’età della stampa. Il modello è distribuito tramite Zenodo con licenza aperta, ma può essere utilizzato solo all’interno della piattaforma Transkribus, dove compare come modello personalizzato per la trascrizione automatica di fonti manoscritte di quell’epoca.
Link al modello: https://zenodo.org/records/18220238
Potrebbe interessarti
Ridurre il “rumore semantico” nei sistemi RAG è fondamentale, soprattutto nei contesti storici. In questo lavoro propongo un approccio basato su vincoli da knowledge graph per migliorare la qualità del retrieval.
Programma ottimo anche se ho qualche difficoltà perchè non riesco a caricare le trascrizioni delle parole già riconosciute. Sia in locale che dal serve mi da la prima trascrizione senza le mie correzzioni. Probabilmente il file .xlm dove vedo le correzzioni sono state effettuate non è al posto giusto e non riesco a farlo apparire sul programma.
Un altro aspetto più importante è il gran numero 15000 delle parole da riconoscere. Non è possibile che il riconoscimento sia graduale. Mi spiego. Se ho individuato un gran nomero di volte una parola (Casa) il programma non potrebbe individuare automaticamente in tutto il testo la parola oppure anche solo il singolo carattere (C). Questo aiuterebbe il riconoscimento di altre parole che iniziano con C e accelerebbe il lungo lavoro di riconoscimento. Grazie.
Ciao Mario e grazie per il commento. Per quanto riguarda il training del riconoscimento non ci sono alternative, è proprio ripetendo n volte la parola “casa” che il modello potrà apprendere quella parola.
Buon giorno. Devo trascrivere documenti manoscritti della seconda metà del xiv secolo.
Come posso fare? Grazie
Salve,
può andare sul sito:
https://www.transkribus.org/plans
per registrarsi, solo il piano individuale è gratuito ma può esserle utile per capire come funziona l’applicazione.
Saluti
Sto leggendo documenti XVII-XVIII secolo (verbali, relazioni, etc) utilizzando come base Transkribus Italian Handwriting M1 ed ottengo risultati accettabili, ma non accurati. Dato che molti documenti sono della stessa mano, e trovo errori sistematici (esempio h=b, s=d, e=i, etc.) si potrebbe creare un modello “integrativo” senza dover costruire un intero nuovo modello? Cioè una aggiunta al modello generico di base che sia in grado di apprendere le specificità di quell’amanuense?
Ciao Enrico,
puoi ottenere un “modello integrativo” senza rifare tutto da zero: fai re-training incrementale partendo dal modello base (es. Italian Handwriting M1) usando pagine Ground Truth della stessa mano. Transkribus consente di aggiungere un base model e ri-addestrare con i tuoi dati; tipicamente bastano ~20+ pagine ben corrette per vedere miglioramenti.
Prova così:
1. Seleziona 20–50 pagine della stessa mano, segmentazione e trascrizione pulite.
2. Avvia “Train Text Recognition Model”, imposta il tuo corpus come Training/Validation e seleziona il base model M1.
3 Allena e usa il modello “figlio” solo su quella mano/serie.
Se vuoi qualcosa di ancora più leggero: crea uno strato di post-correzione sui risultati (regole per confusioni sistematiche tipo h→b, s→d, ecc.). Non migliora il riconoscimento a monte, ma riduce gli errori ricorrenti a valle.