RAG locale con LM Studio. Guida completa
Maximilian Ventura – 16 novembre 2025 – Tutorial

L’idea di interrogare i propri documenti con l’intelligenza artificiale senza caricarli su servizi esterni sta diventando sempre più concreta. Questo articolo è diviso in due parti: nella prima analizziamo cosa è la RAG – Retrieval-Augmented Generation – e perché sta trasformando la ricerca e l’analisi testuale; nella seconda, il tutorial, vediamo come utilizzare LM Studio per creare una RAG locale. Se vuoi leggere solo il tutorial: clicca qui.
Cos’è la RAG
La RAG è una tecnica che combina modelli linguistici (LLM) con un motore di ricerca su fonti esterne in modo che il modello generi risposte basate non solo sulla propria “conoscenza di addestramento”, ma anche su documenti aggiornati e specifici. Un LLM da solo tende a generare risposte plausibili ma non necessariamente corrette o aggiornate, con RAG invece puoi “agganciare” al modello una base conoscitiva esterna, recuperare pezzi pertinenti, e fornire al modello queste informazioni nel prompt, in modo che risponda con maggiore accuratezza e citando le fonti.
Storia
Il termine RAG, acronimo di “Retrieval-Augmented Generation“, è stato introdotto nel 2020 da Patrick Lewis e i suoi collaboratori, si afferma nell’anno seguente con i primi grandi modelli generativi moderni e diventa standard nel 2023–2025 grazie a tool e librerie che lo rendono accessibile fuori dai laboratori. Potremmo definirlo come una una ricetta “general-purpose” di fine-tuning per praticamente qualsiasi LLM collegabile a qualsiasi archivio esterno. Da lì, la tecnica ha guadagnato terreno nell’ingegneria delle AI generative, soprattutto nei contesti enterprise dove serve affidabilità, tracciabilità e aggiornamento dei dati.
Come funziona un sistema RAG
Un sistema RAG è una piccola catena di montaggio che parte dai documenti grezzi e finisce con una risposta in linguaggio naturale.
Per prima cosa c’è la fase di ingestione. Hai un corpus: PDF, pagine web, documenti, ecc . Questi contenuti vengono letti e divisi in pezzi più piccoli, i famosi chunk. Nessun LLM lavora direttamente su un PDF da 200 pagine, lo si taglia in porzioni da qualche centinaio di parole, spesso con un po’ di sovrapposizione tra un pezzo e l’altro per non perdere il filo del discorso.
È bene distinguere i chunks dai token, questi ultimi sono le unità minime con cui il modello legge il testo (pezzi di parola, punteggiatura, simboli), mentre i chunk sono blocchi di testo che decidiamo noi in fase di preparazione dei dati. I token servono al modello per elaborare il contenuto, i chunk servono al sistema RAG per cercare e recuperare i passaggi giusti.
Su questi chunk entra in gioco il livello semantico. Ogni pezzo di testo viene trasformato in un vettore numerico tramite un modello di embedding. È il passaggio chiave, da “parole” a punti in uno spazio ad alta dimensione, dove testi simili finiscono vicini. Tutti questi vettori vengono caricati in un database vettoriale (o comunque in un indice che supporta ricerca per similarità). È qui che si costruisce il “cervello documentale” del sistema RAG.
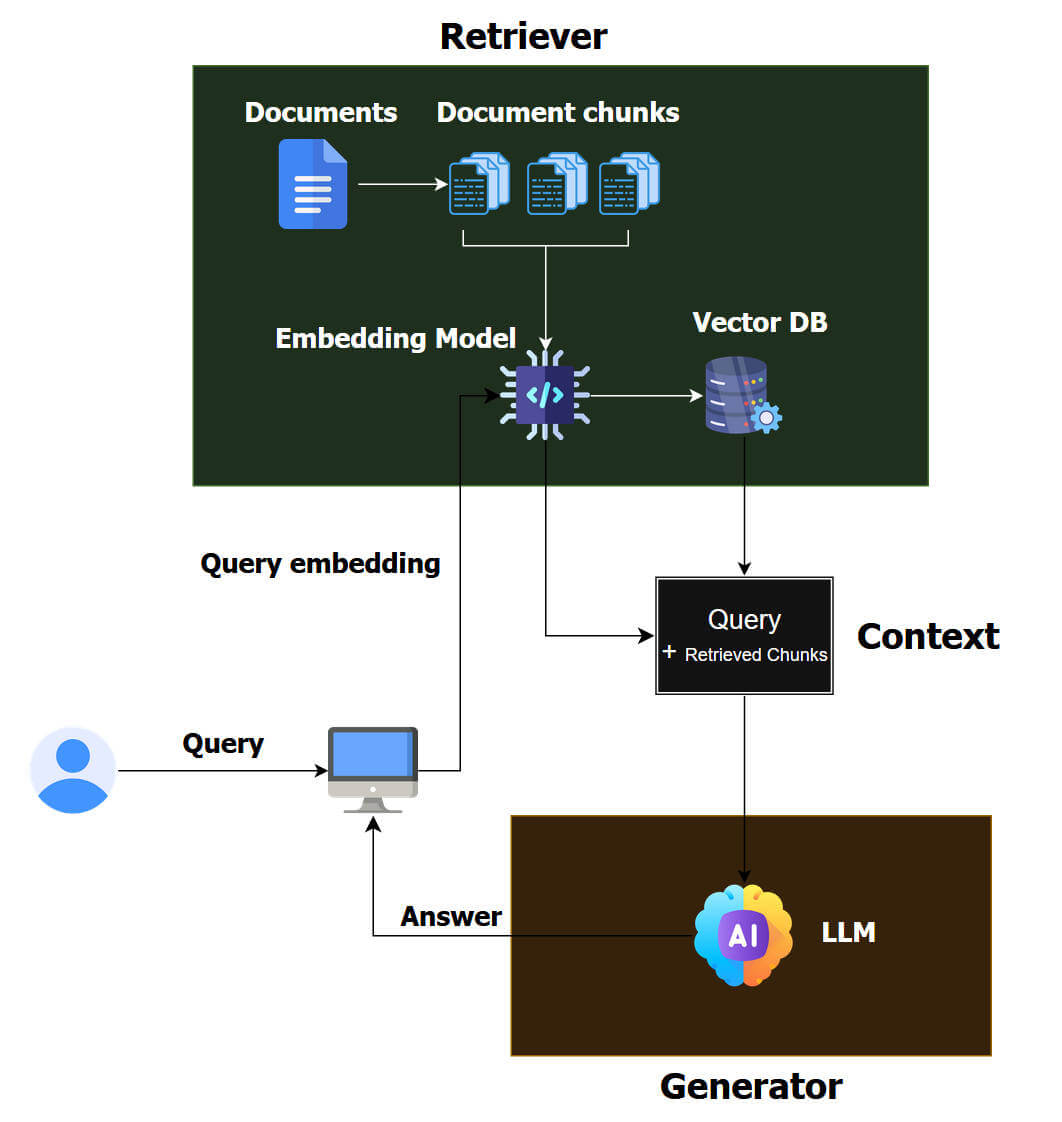
A questo punto immaginiamo il caso in cui l’utente fa una domanda. La query non viene passata direttamente al motore di ricerca come stringa, ma subisce lo stesso trattamento dei documenti. Il modello di embedding la trasforma in un vettore. Poi c’è la fase di retrieval, il sistema cerca, dentro l’indice, i chunk il cui vettore è più vicino a quello della domanda. In alcuni setup si usa un approccio ibrido: similarity semantica + ricerca lessicale tipo BM25, per non perdersi cose ovvie che l’embedding magari sottopesa.
Il risultato del retrieval è una piccola selezione di pezzi: ad esempio i primi 5–20 chunk più rilevanti. Non vengono mostrati così come sono all’utente ma vengono passati al modello come contesto. Qui si palesa meglio il significato della “G” di RAG, cioè la generazione. Il sistema costruisce un prompt arricchito, dentro ci mette la domanda dell’utente, le istruzioni su come rispondere (tono, lingua, formato), e i testi recuperati. In pratica dice al modello: “Ecco la domanda, ecco i documenti pertinenti: rispondi usando solo queste informazioni, citando le fonti quando serve”.
Il modello generativo, a quel punto, fa il suo mestiere, legge la domanda e i chunk, trova connessioni, riassume, mette in ordine, collega passaggi diversi. Non “sa” che dietro c’è un database vettoriale, vede solo un grande prompt in input. Se la pipeline è fatta bene, la risposta che produce non nasce dal nulla ma è fortemente ancorata alle frasi che gli hai messo davanti. Da qui la possibilità di rimandare l’utente alle fonti, puoi mostrare quali documenti hanno alimentato la risposta e a quali passaggi si riferiscono.
In molti sistemi c’è anche un passaggio di post-processing, il sistema filtra contenuti ridondanti, aggiunge riferimenti, forza il modello a dichiarare quando le informazioni non bastano. In ambienti enterprise questo può includere controlli di sicurezza (puoi vedere questo documento sì/no), logging per audit, e feedback dell’utente (questa risposta è utile?) per migliorare ranking e prompt nel tempo.
Tutorial – Come creare una RAG locale con LM Studio
Ci sono diversi software che permettono di creare un sistema RAG locale, ma considero l’installazione e la configurazione di LM Studio più semplici per un utente medio che non ha necessità particolari e magari vuole inziare a sperimentare queste tecnologie. Infatti è sufficiente scaricare il software senza dover installare terze parti.
Sebbene l’interfaccia sia inizialmente un po’ ostica, è utile sapere che ci sono 3 diverse modalità di utilizzo: User (più semplice), Power User (completa) e Developer (sviluppatore), attivabili facilmente dalla barra in basso.
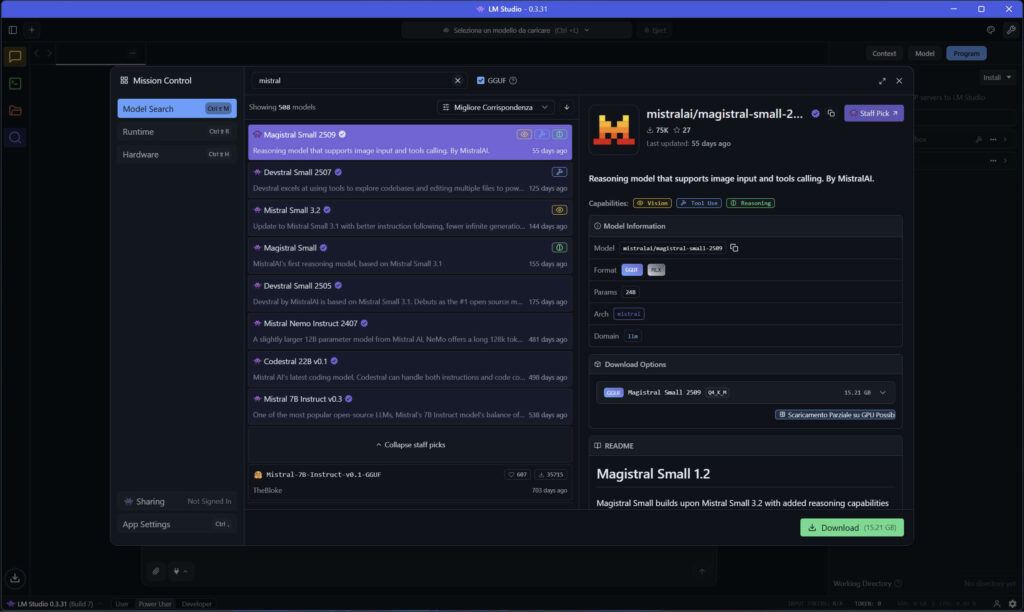
1. Scarica LM Studio
Andiamo sul sito: LM Studio e scarichiamo la versione corrente per il nostro sistema operativo. Installiamo l’applicativo e dopo pochi minuti possiamo già cercare e scegliere uno tra i tanti modelli LLM.
Qualche suggerimento:
- Mistral 7B
- Gemma 3
- GPT-OSS-20B
- Granite 4
- QWEN 3
Su PC con GPU da 8-12 GB di VRAM usa modelli 7B-9B quantizzati. Nella scheda del modello trovi anche se può essere caricato interamente o solo in parte sulla GPU, questo cambia molto la velocità di inferenza.
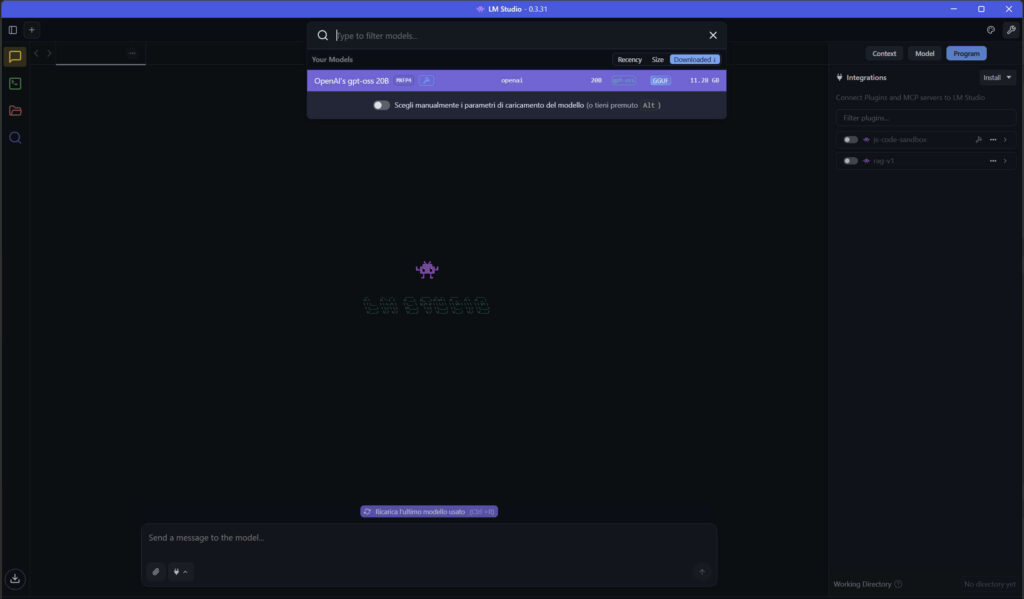
2. Carica il modello LLM
Una volta scelto e scaricato il modello, lo selezioniamo per caricarlo.
3. Scegliamo l’embedder
LM Studio richiede un modello dedicato per gli embeddings.
Consigli embedder:
- Nomic Embed Text v1.5
- Multilingual E5 Large Instruct
NOTA BENE: Una volta scaricato e caricato l’embedder è necessario cliccare su “Status: Stopped” per attivare il server “Status: Running” e far funzionare LM Studio.

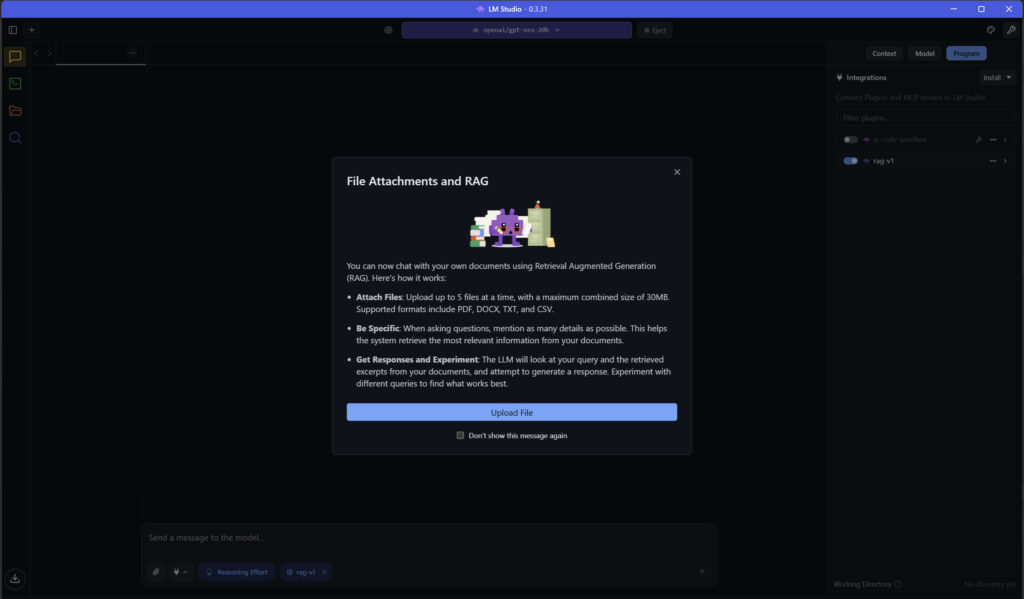
4. Carichiamo i dati e facciamo partire il RAG
Nella colonna di destra attiviamo l’opzione rag v1, apparirà una schermata con le specifiche in termini di tipi di file che si possono caricare e le dimensioni massime supportate.
Conclusioni
La RAG rappresenta un’evoluzione concreta del paradigma dei modelli linguistici generativi, invece di lasciare tutto al modello, si crea una pipeline che lo supporta con conoscenze esterne, aggiornate e verificabili. Questa tecnica offre la possibilità di un’intelligenza generativa più robusta, trasparente e applicabile ai contesti specialistici che richiedono fatti recenti o dominio-specifici.
Una RAG applicata alle digital humanities apre possibilità molto pratiche. Puoi, ad esempio, interrogare un corpus storico senza passare da indici complessi, cercare riferimenti ricorrenti, seguire luoghi o personaggi lungo documenti diversi, confrontare descrizioni provenienti da periodi differenti, oppure isolare rapidamente temi che emergono da centinaia di pagine. È un modo per orientarsi in archivi ampi senza doverli normalizzare o strutturare prima.
Rispetto a una ricerca tradizionale, una RAG ha alcuni vantaggi chiari:
- recupera significato, non solo parole chiave: trova passaggi pertinenti anche se la formulazione cambia;
- collega documenti sparsi: mette insieme frammenti che trattano lo stesso tema;
- gestisce varianti, grafie, nomi non uniformi senza richiedere pre-pulizia pesante;
- riesce a riassumere e sintetizzare insiemi di testi molto grandi;
- lavora sempre sui documenti forniti, quindi resta verificabile.
Ha anche dei limiti:
- se il retrieval recupera chunk sbagliati, la risposta sarà poco utile;
- non sostituisce la lettura critica dei documenti;
- richiede una fase iniziale di ingestione ben fatta (chunking, indice, metadata);
- cambia poco se il corpus è già estremamente semplice o molto breve.
Una RAG locale non è un’alternativa alla ricerca tradizionale, ma un complemento, accelera l’esplorazione, riduce il rumore, evidenzia ciò che è rilevante e permette di lavorare su archivi complessi senza affidare i documenti a servizi esterni.
Ottimo articolo, complimenti, è proprio necessario l’embedder?
Ciao, grazie! Sì, soprattutto per la lingua italiana, per l’inglese puoi usare altri embedder