Knowledge Graph Augmented Generation (K-GAG): generazione aumentata con retrieval deterministico sul Knowledge Graph di Wikidata
Maximilian Ventura – 21 dicembre 2025 – Tutorial

In questo articolo presentiamo Knowledge Graph Augmented Generation (K-GAG), un sistema che combina l’interrogazione del grafo di conoscenza di Wikidata con la generazione in linguaggio naturale tramite LLM controllato (con fallback deterministico). Diversamente dal RAG su documenti non strutturati, il sistema estrae fatti verificabili e li restituisce in italiano con tracciabilità ai QID, producendo risposte più accurate, controllabili e semanticamente coerenti. L’architettura integra tecniche di NLP, indicizzazione locale e selezione guidata dal grafo, riducendo allucinazioni e ambiguità, aprendo nuove prospettive per applicazioni in ambito culturale, educativo e di ricerca.
Introduzione
Questa ricerca è il prosieguo, e in parte l’evoluzione di un progetto precedente in cui abbiamo sperimentato l’uso di LLM per trasformare domande in linguaggio naturale in query SPARQL.
Dalle conclusioni dell’articolo “Dal linguaggio naturale a SPARQL: un approccio controllato basato su LLM per generare query“, emergono i limiti e i problemi di questo approccio, da qui nasce la scelta di esplorare una strategia differente, sviluppata nel presente lavoro.
1. Oltre la RAG tradizionale
L’avvento dei Large Language Models (LLM) ha rivoluzionato il modo in cui interagiamo con l’informazione digitale. Tuttavia, questi modelli soffrono di limitazioni intrinseche: allucinazioni, conoscenza statica legata al data training e (spesso) l’impossibilità di fornire fonti verificabili. Il paradigma Retrieval-Augmented Generation (RAG) ha tentato di risolvere questi problemi recuperando documenti rilevanti da corpus testuali prima della generazione.
Il sistema K-GAG propone un cambio di paradigma fondamentale. Invece di recuperare testo libero, il sistema interroga direttamente un grafo di conoscenza strutturato, nel nostro caso Wikidata, estraendo fatti atomici e verificabili sotto forma di triple semantiche (soggetto-predicato-oggetto).
Questa architettura offre quindi vantaggi distintivi: ogni affermazione nella risposta generata può essere ricondotta a un fatto specifico nel knowledge graph (QID), eliminando ambiguità e garantendo accuratezza fattuale.
Il presente articolo analizza in profondità l’architettura K-GAG, esplorando le innovazioni tecniche che la rendono possibile, le sfide affrontate nella sua implementazione, e le potenzialità future di questo approccio per il panorama dell’intelligenza artificiale conversazionale.
2. Fondamenti Teorici
2.1. Knowledge Graphs e rappresentazione della conoscenza
Un Knowledge Graph è una struttura dati che rappresenta la conoscenza come una rete di entità interconnesse tramite relazioni semantiche. Formalmente, può essere definito come una tripla G = (V, R, E), dove V rappresenta l’insieme dei nodi (entità) e R l’insieme dei tipi di relazione. L’insieme degli archi è definito come E x R x V, ovvero l’insieme delle triple (s, p, o) che descrivono come le entità sono effettivamente collegate tra loro. Questa struttura permette di passare da un modello di dati puramente testuale a uno in cui ogni fatto è un’unità logica atomica e verificabile.
Wikidata contiene oltre 100 milioni di entità identificate da QID e migliaia di proprietà, identificate da PID (per esempio P569 “data di nascita”).
La scelta di Wikidata come backend semantico non è casuale. A differenza di altri knowledge graph proprietari, Wikidata è open-source, collaborativamente mantenuto, e strutturalmente rigoroso. Ogni claim (affermazione) può avere qualificatori (metadati contestuali come date di validità o fonti), permettendo rappresentazioni sfumate della conoscenza che riflettono la complessità del mondo reale.
2.2. Dal linguaggio naturale alle query semantiche
La sfida centrale di K-GAG risiede nella trasformazione di domande espresse in linguaggio naturale in query strutturate capaci di interrogare il knowledge graph. Questo processo, noto come semantic parsing, richiede la comprensione simultanea di sintassi, semantica e pragmatica linguistica, insieme alla mappatura verso l’ontologia specifica del knowledge graph target.
Consideriamo una query apparentemente semplice: “Quando è nato Leonardo da Vinci?”. Il sistema deve:
- identificare “Leonardo da Vinci” come entità target;
- riconoscere “quando è nato” come riferimento alla proprietà P569 (data di nascita);
- disambiguare tra le molteplici entità che potrebbero assomigliare o contenere “Leonardo da Vinci”;
- estrarre il fatto rilevante dal grafo.
Questo processo multi-step richiede un’architettura che il sistema implementa attraverso una pipeline modulare.
3. Architettura del sistema K-GAG
L’architettura K-GAG si articola in quattro fasi principali, ciascuna progettata per affrontare aspetti specifici della trasformazione query-risposta. La modularità del design permette ottimizzazioni indipendenti e facilita l’estensibilità del sistema.
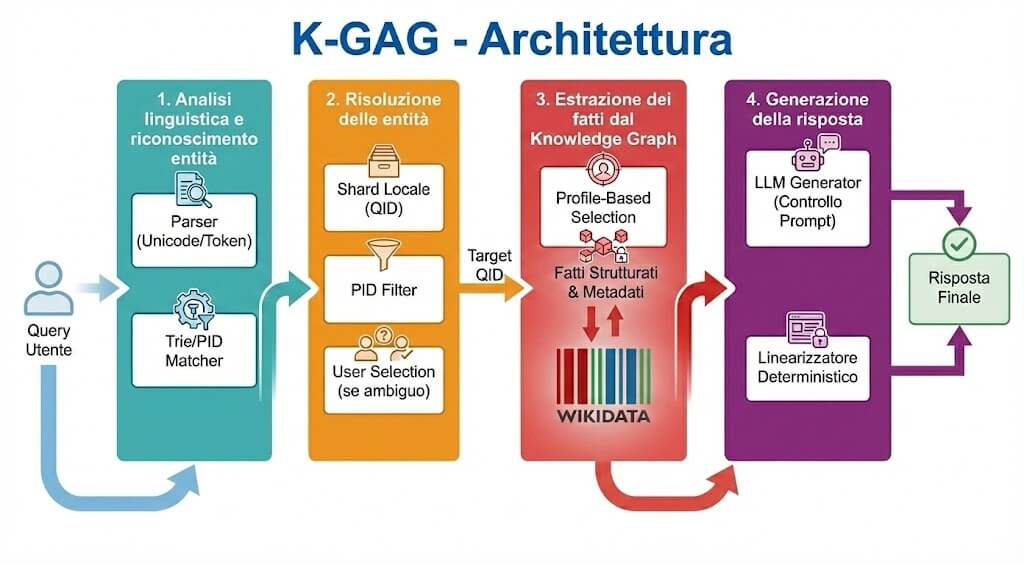
3.1. Fase 1: analisi linguistica e riconoscimento entità
La prima fase del pipeline si occupa della normalizzazione e tokenizzazione del testo in ingresso. Il modulo Parser applica trasformazioni Unicode, rimozione di markup e standardizzazione di caratteri speciali come apostrofi curvi. Questo preprocessing è critico per garantire matching consistente con il dizionario delle proprietà.
Il componente Property Matcher è implementato come struttura dati Trie (albero di prefissi). Il Trie viene popolato con le etichette italiane di circa 1.400 proprietà Wikidata, incluse varianti sinonimiche.
Una caratteristica distintiva del matcher è la strategia di longest-match greedy con selezione non-overlapping. Quando più proprietà potrebbero corrispondere a segmenti sovrapposti della query, l’algoritmo seleziona la corrispondenza più lunga, risolvendo ambiguità comuni dove preposizioni e articoli si combinano in modi complessi.
3.2. Fase 2: risoluzione delle entità
Una volta identificate le proprietà richieste, il sistema deve determinare il soggetto della query. Questa fase implementa tre strategie complementari che si attivano in base al contesto:
- Shard-First Lookup: il sistema mantiene un indice locale partizionato alfabeticamente (shard) contenente i label italiani mappati ai relativi QID. Questo approccio evita chiamate API quando possibile, riducendo latenza e dipendenza da servizi esterni;
- PID-Based Resolution: quando la query contiene proprietà specifiche, il sistema utilizza i PID identificati per filtrare i candidati. Solo entità che possiedono effettivamente quelle proprietà vengono considerate, aumentando la precisione;
- Exact Match Lock: se un candidato ha un label che corrisponde esattamente alla query, il sistema lo seleziona immediatamente tramite un fast-path dedicato.
Il sistema di scoring utilizza una combinazione pesata di copertura dei token e contiguità. Se l’ambiguità persiste, il sistema presenta all’utente una lista di candidati estratti in tempo reale (con descrizione e tipo) per una selezione manuale definitiva.
3.3. Fase 3: estrazione dei fatti dal Knowledge Graph
Con l’entità target identificata, il sistema interroga Wikidata per estrarre i fatti rilevanti attraverso un meccanismo di profile-based selection. Ogni tipologia di entità (persona, architettura, opera, evento) dispone di un profilo dedicato che non si limita a dare priorità alle proprietà più significative, ma definisce anche quali qualificatori estrarre per contestualizzare il dato.
Ad esempio, per i profili “persona” o “evento”, il sistema ricerca attivamente i qualificatori P580 (data di inizio) e P582 (data di fine). Questa capacità permette di andare oltre la semplice tripla piatta, consentendo di costruire linee temporali accurate o di contestualizzare i fatti (come incarichi professionali o periodi di residenza) all’interno di un intervallo cronologico preciso. I fatti estratti preservano così la ricchezza semantica di Wikidata, includendo metadati sulla precisione temporale e sul grado di affidabilità (rank) dell’affermazione.
3.4. Fase 4: generazione della risposta
L’ultima fase trasforma i fatti strutturati in una risposta in linguaggio naturale. Il sistema utilizza un approccio duale: un LLM come generatore primario e un linearizzatore deterministico come fallback.
Il prompt engineering è stato attentamente calibrato per garantire fedeltà ai dati. L’LLM riceve istruzioni esplicite di:
- utilizzare esclusivamente i fatti forniti senza aggiungere informazioni;
- rispettare precisioni temporali e numeriche esatte;
- produrre testo discorsivo italiano evitando elenchi puntati.
L’attivazione del percorso deterministico non è un evento generico, ma segue una logica a cascata governata da trigger specifici nel modulo di gestione della risposta. Il sistema instrada la richiesta verso il linearizzatore in tre scenari distinti:
- Assenza di evidenze: se l’array dei fatti estratti è vuoto, il sistema bypassa la chiamata all’LLM per ottimizzare le risorse;
- Eccezioni tecniche: in caso di timeout, errori di rete o fallimenti delle API del modello linguistico intercettati dai blocchi di gestione errori;
- Incongruenza dell’output: qualora l’LLM produca una risposta vuota o non conforme ai criteri di validazione.
In tali circostanze, il componente opera come un motore di template semantici che analizza la natura della proprietà per generare frammenti di frasi naturali (gestendo, ad esempio, espressioni come ‘nato il’ o ‘di professione’). Un punto di forza di questo modulo è la gestione avanzata delle date e delle quantità: il sistema converte i formati grezzi di Wikidata in italiano esteso (es. 15 aprile 1452 invece di 1452-04-15), garantendo che la risposta, sebbene meno fluida di quella generata dall’LLM, mantenga un’elevata leggibilità e precisione.
4. Innovazioni Tecniche Distintive
L’architettura di K-GAG si articola su alcune componenti chiave, progettate per ottimizzare l’interazione tra i modelli linguistici e i dati strutturati:
4.1. Indicizzazione locale sharded
L’approccio di sharding alfabetico dell’indice QID risolve il problema della scalabilità, invece di caricare in memoria l’intero mapping label-QID, il sistema carica solo gli shard necessari in base alla richiesta e li mantiene in cache finché l’istanza è attiva. Questo design permette startup rapidi e footprint di memoria controllato, caratteristiche essenziali per deployment serverless.
4.2. Disambiguazione semantica multi-strategia
Per dare un grado maggiore di controllo, la risoluzione è guidata dall’utente: generiamo i candidati con un indice locale e uno scoring (copertura e contiguità dei token), attiviamo un fast-path in caso di exact match e, se presenti, applichiamo vincoli su PID. Mostriamo quindi una pagina con tutti i risultati (label, QID e una breve descrizione) e l’utente sceglie il soggetto corretto.
4.3. Esplorazione dinamica e incrementale del grafo
Oltre alla risposta testuale, il sistema genera una rappresentazione grafica interattiva delle relazioni estratte. I nodi rappresentano le entità (categorizzate cromaticamente per tipo: persona, luogo, opera) e gli archi definiscono le proprietà semantiche.
A differenza di una visualizzazione statica, l’architettura permette un’espansione incrementale del grafo: attraverso la funzione di neighbor expansion, l’utente può cliccare su qualsiasi nodo periferico per attivare nuove query asincrone verso il backend. Questo processo carica dinamicamente nuovi fatti e nodi correlati, permettendo di navigare i collegamenti di Wikidata senza mai lasciare l’interfaccia. Tale approccio trasforma la consultazione passiva in un processo di scoperta attiva, dove l’utente può tracciare percorsi di conoscenza personalizzati ed esplorare connessioni semantiche non immediatamente evidenti nella risposta testuale.
5. Sfide e limitazioni
Nonostante i risultati promettenti, l’implementazione di K-GAG ha evidenziato sfide tecniche significative che rappresentano aree di miglioramento futuro.
- Normalizzazione linguistica: l’italiano ha diacritici e contrazioni (“perché”, “dell’…”). Nel sistema distinguiamo due livelli:
- Matcher delle proprietà (PID): applichiamo una normalizzazione canonica che rimuove i diacritici e uniforma varianti/apostrofi per massimizzare il riconoscimento delle espressioni (“data di nascita”, “nato a…”);
- Lookup delle entità (QID): manteniamo gli accenti e le forme corrette delle label; la tolleranza agli errori deriva da alias multipli e dallo scoring (copertura/contiguità), non dalla rimozione dei diacritici. Questo compromesso aumenta il recall sul lato proprietà senza degradare la resa dei nomi propri. L’ortografia finale è garantita in uscita dall’LLM controllato o dal linearizzatore deterministico.
- Ottimizzazione della latenza e carico API: l’interazione con database massivi come Wikidata e la generazione tramite LLM introducono sfide intrinseche di latenza. Per mitigare questi colli di bottiglia, il sistema adotta un’architettura ibrida: l’uso di shard file locali per la risoluzione dei QID e l’indicizzazione preventiva dei PID permettono di ridurre al minimo le chiamate API esterne durante la fase di analisi.
- Evoluzione della copertura semantica: il dizionario delle proprietà (PID), sebbene esteso a oltre 1.400 concetti curati, non può coprire l’intera gamma delle formulazioni linguistiche italiane. Espressioni colloquiali, regionalismi o terminologia tecnica specialistica potrebbero non trovare una corrispondenza immediata nel Trie di sistema. Per superare questo limite, l’architettura è predisposta per l’integrazione di un sistema di analisi dei feedback utente.
- Reasoning complesso: l’attuale implementazione è ottimizzata per query a “singolo hop” (soggetto → proprietà → valore), potenziata dall’estrazione di qualificatori. Tuttavia, query che richiedono un reasoning multi-hop o aggregazioni numeriche complesse non sono ancora supportate nativamente e rappresentano la prossima frontiera dello sviluppo della logica di navigazione del grafo.
6. Confronto con Approcci Esistenti
Per comprendere il funzionamento di K-GAG è utile confrontarlo con i sistemi RAG tradizionali. Mentre la RAG classica si basa sull’indicizzazione di vasti corpus documentali non strutturati, un approccio che risulterebbe dispersivo e computazionalmente oneroso se applicato all’intera scala di Wikidata, il sistema K-GAG risponde all’esigenza di un controllo diretto sulle variabili semantiche.
Invece di affidarsi esclusivamente a calcoli probabilistici su vettori di testo, l’architettura proposta utilizza il grafo per isolare fatti certi, riducendo la latenza e garantendo la verificabilità del dato. Questo approccio non sostituisce la RAG, ma ne evolve l’applicazione in contesti dove la precisione strutturale è prioritaria rispetto alla navigazione di testi discorsivi.
Tale rigore è reso possibile da una gestione localizzata dei dati del grafo, che trasforma l’immensa base di conoscenza di Wikidata in un set di informazioni gestibili. Attraverso lo scaricamento preventivo di liste selezionate di PID e QID (shard locali), il sistema non solo minimizza le chiamate API esterne, ma garantisce un rigore fattuale che un sistema RAG basato su testo libero difficilmente potrebbe mantenere con lo stesso dispendio di risorse.
| Caratteristica | RAG Tradizionale | K-GAG |
|---|---|---|
| Gestione Dati | Richiede GB/TB di documenti | Ottimizzata via Shard (PID/QID locali) |
| Controllo | Statistico (basato su embedding) | Deterministico (liste curate) |
| Efficienza API | Alta (molte call o vector lookup) | Bassa (minimizzata da lookup locale) |
| Scalabilità | Molto costosa su grafi enormi | Sostenibile (approccio “Lite”) |
7. Direzioni Future
L’attuale implementazione di K-GAG rappresenta un proof-of-concept robusto che dimostra la fattibilità dell’ancoraggio strutturato. Numerose direzioni di sviluppo potrebbero estenderne le capacità critiche:
- Multi-hop reasoning: l’evoluzione naturale del sistema prevede il superamento della query a singolo salto. Implementare la capacità di navigare catene relazionali (es. “Soggetto A → Proprietà X → Soggetto B → Proprietà Y”) permetterebbe di risolvere interrogazioni complesse che richiedono l’unione di più triple semantiche;
- Federazione di Knowledge Graph: l’architettura a shard e PID è pronta per essere estesa a grafi di dominio specifico. La federazione permetterebbe di mantenere l’interfaccia unificata ampliando drasticamente la profondità dei dati disponibili;
- Apprendimento continuo: L’integrazione di un modulo di analisi dei miss (proprietà o entità non risolte) permetterebbe di espandere dinamicamente il dizionario dei sinonimi e di affinare gli algoritmi di disambiguazione basandosi sulle reali interazioni degli utenti;
- Tracciamento avanzato: oltre alla risposta testuale, lo sviluppo futuro mira a esplicitare il processo di reasoning, visualizzando non solo il grafo finale ma anche il percorso logico compiuto per selezionare determinati fatti rispetto ad altri, aumentando la fiducia dell’utente nel sistema.
8. Conclusioni
L’approccio K-GAG) propone un metodo per integrare i modelli di linguaggio con basi di conoscenza strutturate. Spostando l’attenzione dal recupero di documenti testuali all’interrogazione diretta di grafi, il sistema punta a limitare alcuni problemi tipici della generazione neurale, come l’allucinazione dei dati e la difficoltà nel citare fonti puntuali.
L’implementazione presentata dimostra come sia possibile costruire un’architettura funzionale integrando diverse tecniche: il matching delle proprietà tramite Trie, la risoluzione delle entità basata su shard file locali e una fase di generazione che prevede un fallback deterministico. Questa struttura non cerca di competere con la scala dei sistemi RAG generalisti, ma offre un’alternativa per contesti in cui la precisione del dato e il risparmio delle risorse computazionali sono prioritari rispetto alla vastità del corpus trattato.
Le criticità rilevate, in particolare la latenza nelle chiamate API e la complessità della navigazione multi-hop, definiscono i prossimi passi della ricerca. Tuttavia, i risultati ottenuti confermano che l’uso di filtri semantici e liste di proprietà curate è una strada percorribile per rendere le risposte degli LLM più verificabili.
In sintesi, Knowledge Graph Augmented Generation si offre come uno strumento di supporto alla consultazione di dati aperti, dove la trasparenza del processo di estrazione e il legame con identificatori univoci (QID) rappresentano i requisiti minimi per un’interazione affidabile con la conoscenza strutturata.